Dashboards
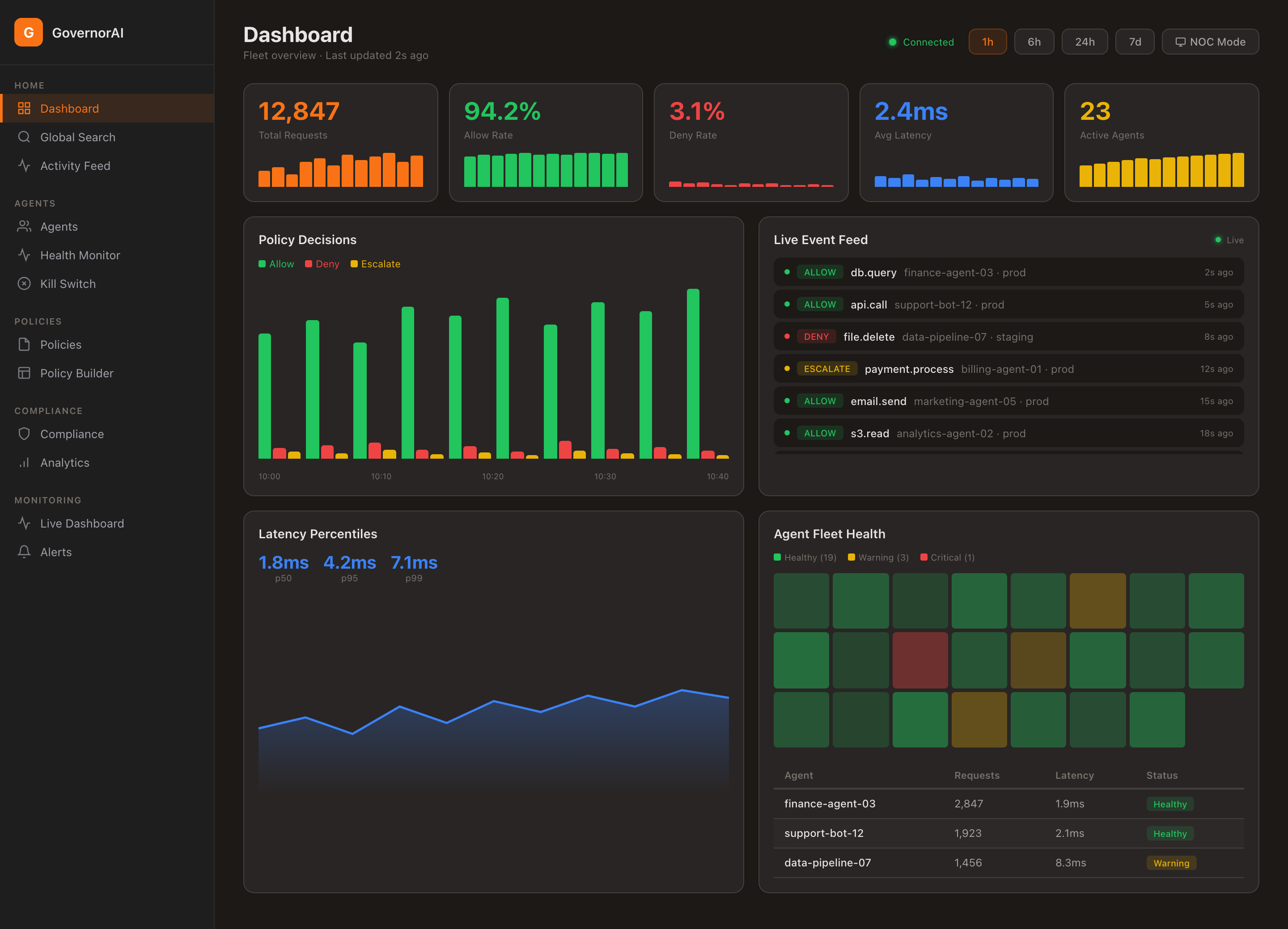
Real-Time Governance Dashboard
A single pane of glass for your entire AI fleet. Agent inventory, session tracking, policy hit rates, anomaly scores, and operational health—all in real time.
- Agent inventory and health status
- Live session tracking
- Policy evaluation heat maps
- Anomaly score trending